What Cactus users actually want
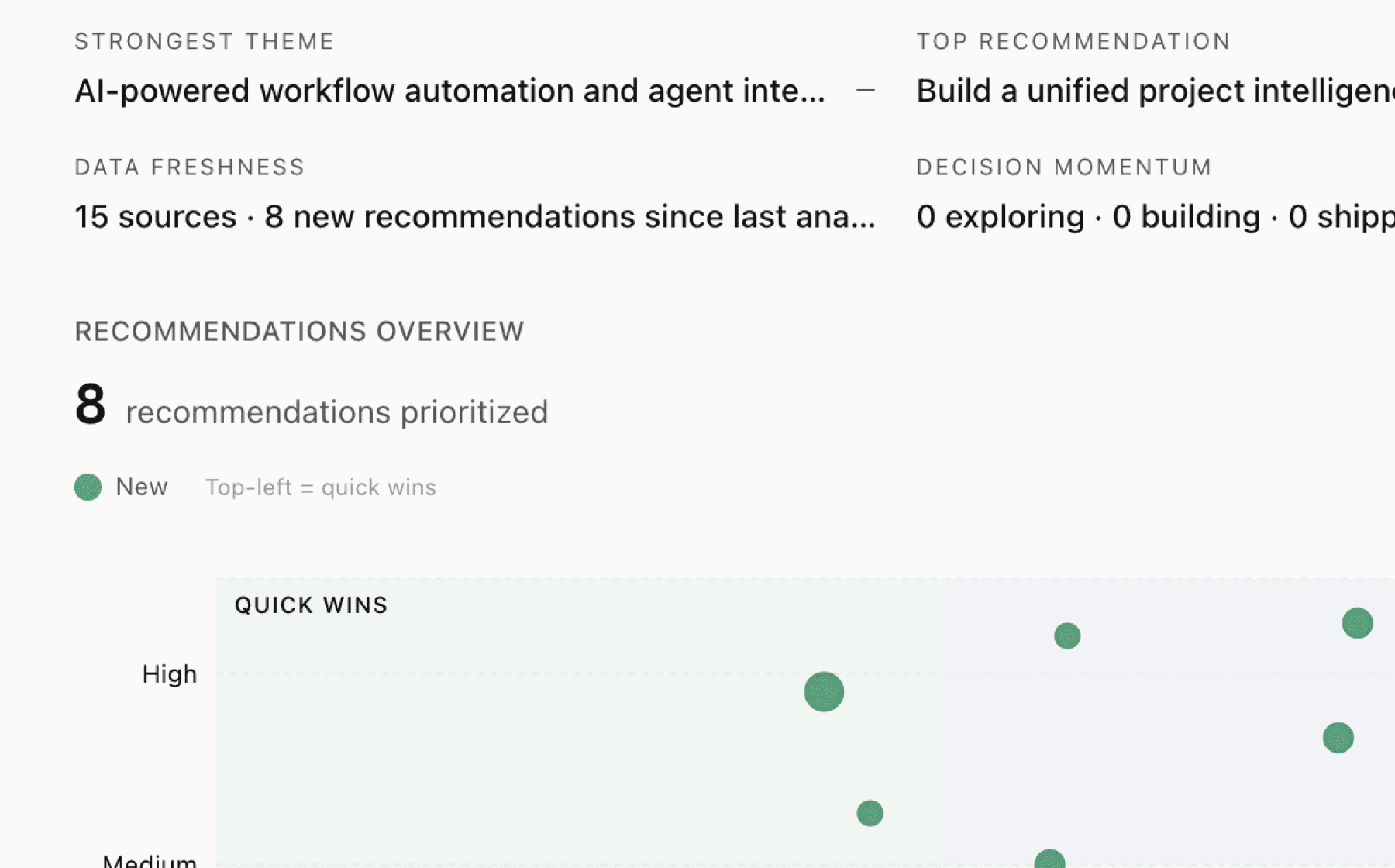
Mimir analyzed 8 public sources — app reviews, Reddit threads, forum posts — and surfaced 14 patterns with 7 actionable recommendations.
This is a preview. Mimir does this with your customer interviews, support tickets, and analytics in under 60 seconds.
Top recommendation
AI-generated, ranked by impact and evidence strength
Create benchmark-driven model recommendation system showing performance by device tier
High impact · Medium effort
Rationale
The product's core differentiator is sub-50ms latency and 18 tokens/sec throughput, but developers face a critical decision point: which model to deploy for their target devices. Evidence shows performance varies dramatically — from 18 tokens/sec for Qwen3 4B on iPhone 16 Pro Max to 394 tokens/sec for Qwen3 0.6B on unspecified consumer hardware. The current documentation requires developers to infer this themselves.
With 70% of the market on budget and mid-range devices, incorrect model selection directly impacts engagement and retention. A developer choosing a 4B model for their Android user base may ship a sluggish experience when a 600M model would have delivered the responsiveness users expect.
Leverage the existing 22-device benchmark data to build an interactive tool that lets developers input their target device profile and receive a ranked recommendation of models with predicted latency and throughput. Surface this during integration and in the dashboard alongside telemetry showing actual performance in production.
Projected impact
The full product behind this analysis
Mimir doesn't just analyze — it's a complete product management workflow from feedback to shipped feature.
Evidence-backed insights
Every insight traces back to real customer signals. No hunches, no guesses.

Chat with your data
Ask follow-up questions, refine recommendations, and capture business context through natural conversation.

Specs your agents can ship
Go from insight to implementation spec to code-ready tasks in one click.
This analysis used public data only. Imagine what Mimir finds with your customer interviews and product analytics.
Try with your dataMore recommendations
6 additional recommendations generated from the same analysis
The SDK offers four inference modes, but developers lack guidance on which to use. This is a consequential decision — choosing LOCAL when the device can't handle it creates a broken experience, while choosing REMOTE_FIRST sacrifices the latency advantage that drives engagement.
React Native developers remain on v0 while Flutter and Kotlin users access v1's performance improvements and consistent APIs. This fragmentation creates a two-tier developer experience where a significant portion of the user base cannot access the product's core value — optimized ARM-CPU kernels and sub-50ms latency.
RAG is marked as coming soon but represents a critical capability gap. The product enables embedding generation and semantic search primitives, but developers need a complete solution to build context-aware applications that reference proprietary knowledge bases.
The Flutter SDK promotes a 5-minute video walkthrough, but this is a long commitment before a developer sees working code. Product managers and founders evaluating the SDK need immediate proof that it delivers on the latency promise.
Agent Builder Canvas is mentioned as a feature for creating complex workflows, but its current state and capabilities are unclear. Tool calling and agentic workflows are positioned as differentiators, yet function calling remains marked as work in progress in Kotlin.
The telemetry system tracks throughput, latency, and error rates, but the dashboard view described suggests aggregated metrics. Product managers need to see performance from the user perspective — how responsive is the experience for specific features on specific devices.
Insights
Themes and patterns synthesized from customer feedback
Video walkthroughs, self-documenting headers, visualization tools, and active community channels (Discord, GitHub) lower barriers to adoption and integration. Reduced friction in getting started accelerates time-to-first-value and improves retention.
“Cactus exposes 4 levels of abstraction: FFI, Engine, Graph, and Kernels for flexible integration”
Embedded support for embedding generation, semantic search, model caching, and RAG enables developers to build context-aware AI applications with enterprise data integration. These features unlock use cases requiring knowledge retrieval and personalization.
“Model information includes size, supported features (tool calling, vision), and download status”
Support for iOS 12.0+ and Android API 24+ with benchmarking across 22 real devices including folding phones provides confidence in production deployment. Real-world validation reduces launch risk and supports retention through reliability.
“Platform requirements: iOS 12.0+ and Android API level 24+”
Cactus Graph functions as a foundational numerical computing framework for mobile devices, enabling custom operations beyond standard inference. This extensibility positions the product for advanced AI workloads and technical differentiation.
“Cactus Graph functions as a general numerical computing framework similar to JAX for phones”
Required permissions (INTERNET, RECORD_AUDIO) and default parameters enable proper mobile device integration for audio and network capabilities. Standard configuration reduces integration overhead.
“Cactus SDKs process inference tasks in production”
Cactus Compute dashboard provides centralized monitoring, management, and deployment capabilities with standard authentication. Project management tooling supports operational oversight for applications in production.
“Cactus Compute offers a project monitoring dashboard accessible via email/password or GitHub OAuth”
Low-level token processing and perplexity calculation tools support advanced developer use cases and model diagnostics. These utilities serve specialized workflows for power users and model optimization.
“Tokenization and score window utilities available for low-level token processing and perplexity calculations”
GitHub repository engagement and community metrics indicate ecosystem strength and market traction. Project visibility supports developer awareness and confidence in the platform.
“GitHub repository stars for Cactus project”
The SDK enables vision, speech, text, and tool-calling capabilities alongside core inference, allowing developers to build sophisticated AI-powered mobile applications. This breadth of features reduces friction for complex use cases and increases retention through feature richness.
“Vision-capable models support multimodal analysis with image inputs”
Multiple inference modes (LOCAL, REMOTE, LOCAL_FIRST, REMOTE_FIRST) with intelligent fallback to cloud providers ensure reliable operation across varying device capabilities and connectivity. This flexibility maintains user engagement even under poor network or low-resource conditions.
“Cloud fallback capability for longer or asynchronous tasks when on-device inference insufficient”
Unified APIs across Flutter, React Native, Kotlin Multiplatform, and native C++ with v1 addressing v0 inconsistencies enable developers to deploy confidently across platforms. Consistency reduces integration friction and accelerates time-to-market.
“Cactus exposes 4 levels of abstraction: FFI, Engine, Graph, and Kernels for flexible integration”
Built-in monitoring dashboards, timing metrics, and engagement tracking provide granular visibility into model performance and user behavior. This telemetry enables data-driven optimization decisions that directly improve engagement and retention.
“SDK provides timing metrics including time to first token and tokens per second”
Zero data transmission by default with all inference happening on-device addresses privacy concerns and enables deployment of sensitive workloads on mobile. This design removes regulatory and trust barriers for sensitive applications.
“Cactus is designed bottom-up with no dependencies for all mobile devices”
The product delivers sub-50ms time-to-first-token and 18 tokens/sec throughput through optimized ARM-CPU kernels, directly enabling responsive user experiences critical to engagement. This technical achievement across budget and high-end devices is the foundational differentiator.
“SDK provides streaming completions for real-time token generation with callbacks”
Run this analysis on your own data
Upload feedback, interviews, or metrics. Get results like these in under 60 seconds.