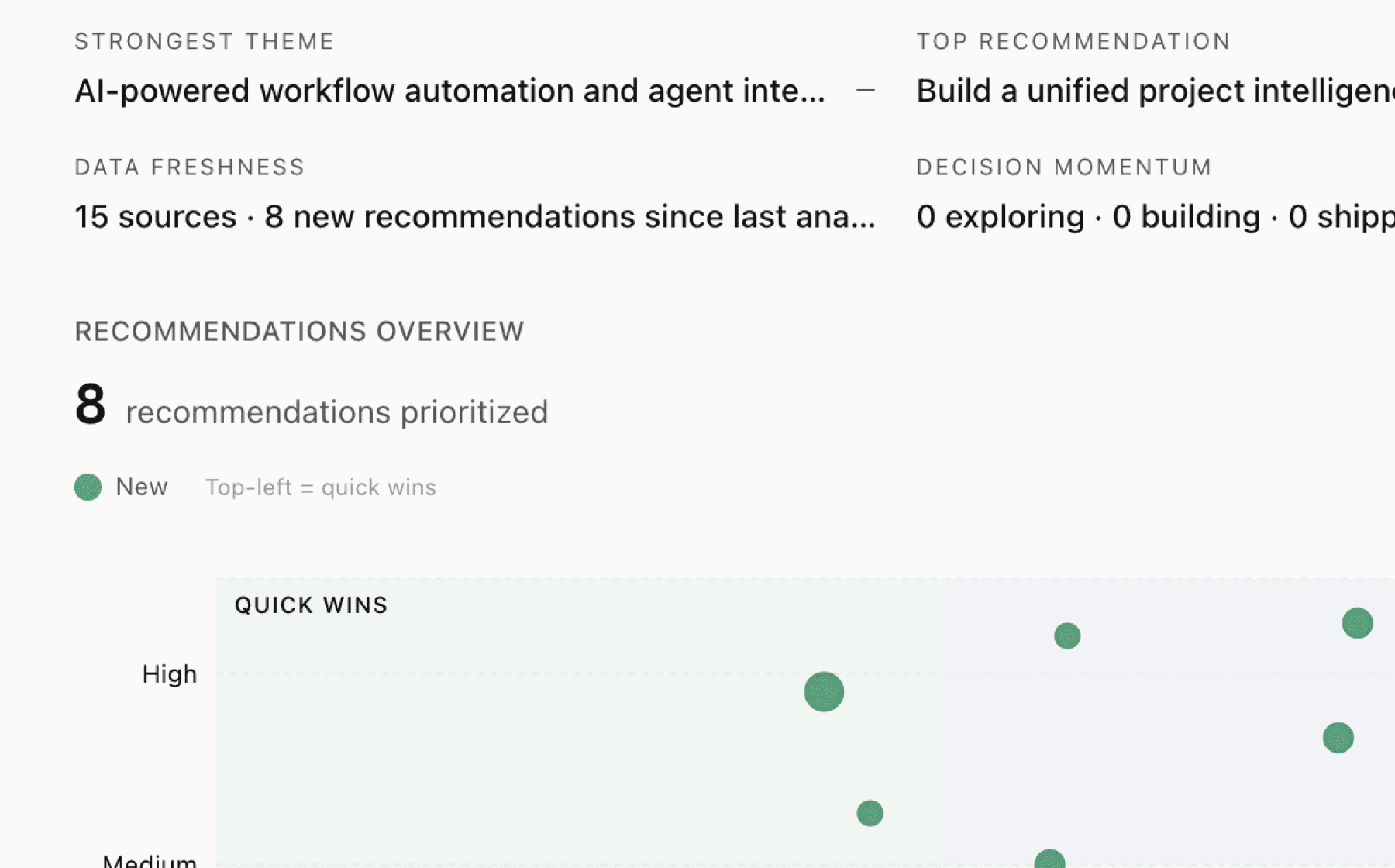
What Outerport users actually want
Mimir analyzed 8 public sources — app reviews, Reddit threads, forum posts — and surfaced 13 patterns with 6 actionable recommendations.
This is a preview. Mimir does this with your customer interviews, support tickets, and analytics in under 60 seconds.
Top recommendation
AI-generated, ranked by impact and evidence strength
Build self-service deployment wizard for on-premises and VPC environments with compliance templates
High impact · Large effort
Rationale
Fortune 500 enterprises and banks are already using Outerport in production for mission-critical compliance and policy work, but on-premises deployments place full responsibility for security, backups, and system requirements on the customer. This creates a high-friction adoption barrier for regulated industries that need the product most.
A guided deployment experience with pre-configured compliance templates (SOC2, GDPR, HIPAA) would reduce time-to-production from weeks to days while maintaining the security posture these customers require. The wizard should handle infrastructure provisioning, security hardening, backup configuration, and compliance documentation generation.
This directly addresses the gap between strong enterprise demand and operational complexity, turning deployment flexibility from a liability into a competitive advantage. It enables faster land-and-expand motion in regulated sectors where Outerport has already proven product-market fit.
Projected impact
The full product behind this analysis
Mimir doesn't just analyze — it's a complete product management workflow from feedback to shipped feature.
Evidence-backed insights
Every insight traces back to real customer signals. No hunches, no guesses.

Chat with your data
Ask follow-up questions, refine recommendations, and capture business context through natural conversation.

Specs your agents can ship
Go from insight to implementation spec to code-ready tasks in one click.
This analysis used public data only. Imagine what Mimir finds with your customer interviews and product analytics.
Try with your dataMore recommendations
5 additional recommendations generated from the same analysis
Users can opt out of third-party AI integrations only by emailing dpo@outerport.com, and data may be transferred across multiple countries including the United States. This manual process creates compliance friction for regulated customers who need granular control over where their data is processed and which AI providers handle inference.
The core differentiation is accuracy in long-document retrieval without hallucination, but prospects evaluating the product have no way to validate these claims on their own data before committing. Vector RAG and long-context approaches fail in measurable ways—hallucinated citations, accuracy degradation after 40k tokens, inability to handle indirect causation—but these failure modes only become visible after deployment.
Vector RAG cannot reliably complete tasks requiring metadata understanding like finding section reference numbers, and returns top-K results as unordered text blobs. Meanwhile, Outerport surfaces inter-document references like assembly drawings pointing to parts and P&ID symbols referencing tables, but users have no interface to explore these relationships interactively.
Time-to-first-token can be reduced from 10+ seconds to 1-2 seconds using KV cache preprocessing, but this capability appears to be internal infrastructure rather than a user-facing feature. Long-context retrieval on 128k tokens takes 3 minutes on two A100 GPUs, making real-time applications impossible without optimization.
The founding team has deep expertise with 4000+ citations and 8000+ GitHub stars, and the architectural insights about vector RAG limitations are compelling, but this expertise is not widely visible in the market. The technical blog content exists but is not packaged as authoritative thought leadership that would attract engineering leads and technical founders.
Insights
Themes and patterns synthesized from customer feedback
Outerport reserves the right to suspend or limit access if usage exceeds Order Form limits and collects aggregated, anonymized Service Analytics to improve offerings. The service prohibits use for medical, financial, legal, emergency response, or autonomous weapons applications. Outerport is not responsible for third-party service availability or compatibility, and customers retain intellectual property rights to their own data while Outerport retains all IP rights in the Services and Software.
“Service volume limitations exist and Outerport reserves right to suspend/limit access if usage exceeds Order Form limits”
Outerport acts as a Data Processor for customers who are Data Controllers under GDPR, handling collection, processing, and storage of personal information including name, email, company name, physical address, birthdate, phone number, and usage analytics. The company shares personal information with third-party service providers (payment processing, data storage) under confidentiality agreements and may transfer, store, and process data across multiple countries including the United States.
“Outerport acts as a Data Processor for customers who are Data Controllers under GDPR, handling personal information collection, processing, and storage.”
In addition to automated API-based parsing, Outerport offers human-assisted document conversion services, providing flexibility for organizations that need manual verification or handling of complex or edge-case documents. This hybrid approach extends the product's utility beyond fully automated workflows.
“Supports human-assisted document conversion services in addition to API parsing”
The product enables vision-powered tools for AI agents that prevent hallucinations through structured visual understanding with bounding boxes and metadata, moving beyond unstructured image processing to provide machine-understandable context for agent reasoning.
“Vision-powered tools for AI agents that prevent hallucinations through structured visual understanding with bounding boxes and metadata”
Outerport implements KV cache preprocessing to reduce time-to-first-token from over 10 seconds to 1-2 seconds by reusing cached semantic information across multiple questions. This optimization enables more responsive agentic search interactions without requiring complete re-computation for each query.
“KV cache preprocessing enables time-to-first-token reduction from 10+ seconds to 1-2 seconds by reusing cached semantic information across multiple questions”
Vector RAG systems struggle with indirect causation detection, embedding unreliability across similar queries, and lack of metadata understanding for structured tasks (e.g., finding section reference numbers). The approach also presents poor user experience by returning top-K results as unordered text blobs with many hard-to-tune decision parameters (window size, overlap, metadata, query translation, reranking).
“Vector RAG cannot handle indirect causations—embeddings for indirect causes may not be similar to embeddings for effects”
CEO Towaki Takikawa brings deep 3D generative AI and computer vision expertise from NVIDIA research with 4000+ citations across top-tier conferences (CVPR, ICCV, SIGGRAPH) and 8000+ GitHub stars on open source 3D ML software. CTO Allen Wang has LLM and computer vision experience from Tome and Embark Trucks, plus large-scale data science infrastructure experience from LinkedIn, Meta, and Royal Bank of Canada.
“CEO Towaki Takikawa has deep expertise in 3D generative AI and computer vision from NVIDIA research background”
Outerport does not use customer data to train AI models and does not share data with third-party AI providers for model improvement. However, user-uploaded data may be sent to third-party model providers (e.g., OpenAI, Anthropic) for inference-only purposes if the user executes their project. Users can opt-out of data being sent to third-party AI integrations and receive marketing emails by contacting dpo@outerport.com. The company maintains a commercially reasonable information security program and commits to rapid breach notification.
“Outerport does not use customer data to train AI models and does not share data with third-party AI providers for model improvement purposes.”
Outerport offers multiple deployment options including Cloud Services, On-Premise Software, VPC, and on-site engineering for customization. For on-premises deployments, customers assume full responsibility for system requirements, security, backups, and data protection, while Outerport provides integration via REST API, SDK, Services, and Search APIs.
“Deployment options include Cloud, On-Premise, VPC, and on-site engineering for customization”
Outerport is used by Fortune 500 enterprises and startups across banking, manufacturing, architecture/engineering, and MEP (mechanical, electrical, plumbing) sectors. Primary use cases include internal search systems, compliance automations, and document generation, with validated deployment in production environments handling mission-critical workloads.
“Used by Fortune 500 enterprises and startups in banking, manufacturing, architecture/engineering, and MEP sectors”
Outerport's core capability enables AI agents to retrieve information from tens of thousands of pages using chain-of-memory reasoning and structured memory, directly addressing hallucination and accuracy issues that plague vector RAG systems in mission-critical applications. This positions the product as a solution for compliance, legal, and policy-understanding use cases where precision is non-negotiable.
“Outerport enables AI agents to retrieve information from tens of thousands of pages using chain-of-memory reasoning without hallucinating”
Long-context approaches face multiple hard constraints: computational cost (O(n²) attention), hard token limits (128k ceiling vs. 200k+ document lengths), and accuracy degradation after 40k+ tokens. Outerport addresses these by decomposing question-answering into planning, retrieval, and reasoning steps with different models, using techniques like KV cache preprocessing to reduce time-to-first-token from 10+ seconds to 1-2 seconds.
“Long-context retrieval is computationally expensive; attention is O(n²) and processing 128k tokens on 70B model takes 3 minutes on 2 A100 GPUs”
Outerport converts diagrams, CAD files, P&ID diagrams, process flows, GD&T drawings, electrical CAD documents, and tables into queryable structured data, with parsing accuracy exceeding typical vision-language models. The product surfaces inter-document references and links (e.g., assembly drawings to parts, P&ID symbols to tables), enabling downstream RAG and agentic search capabilities.
“Product extracts structured data from diagrams, CAD, tables, P&ID diagrams, process flows, GD&T drawings, and electrical CAD documents”
Run this analysis on your own data
Upload feedback, interviews, or metrics. Get results like these in under 60 seconds.