What s2.dev users actually want
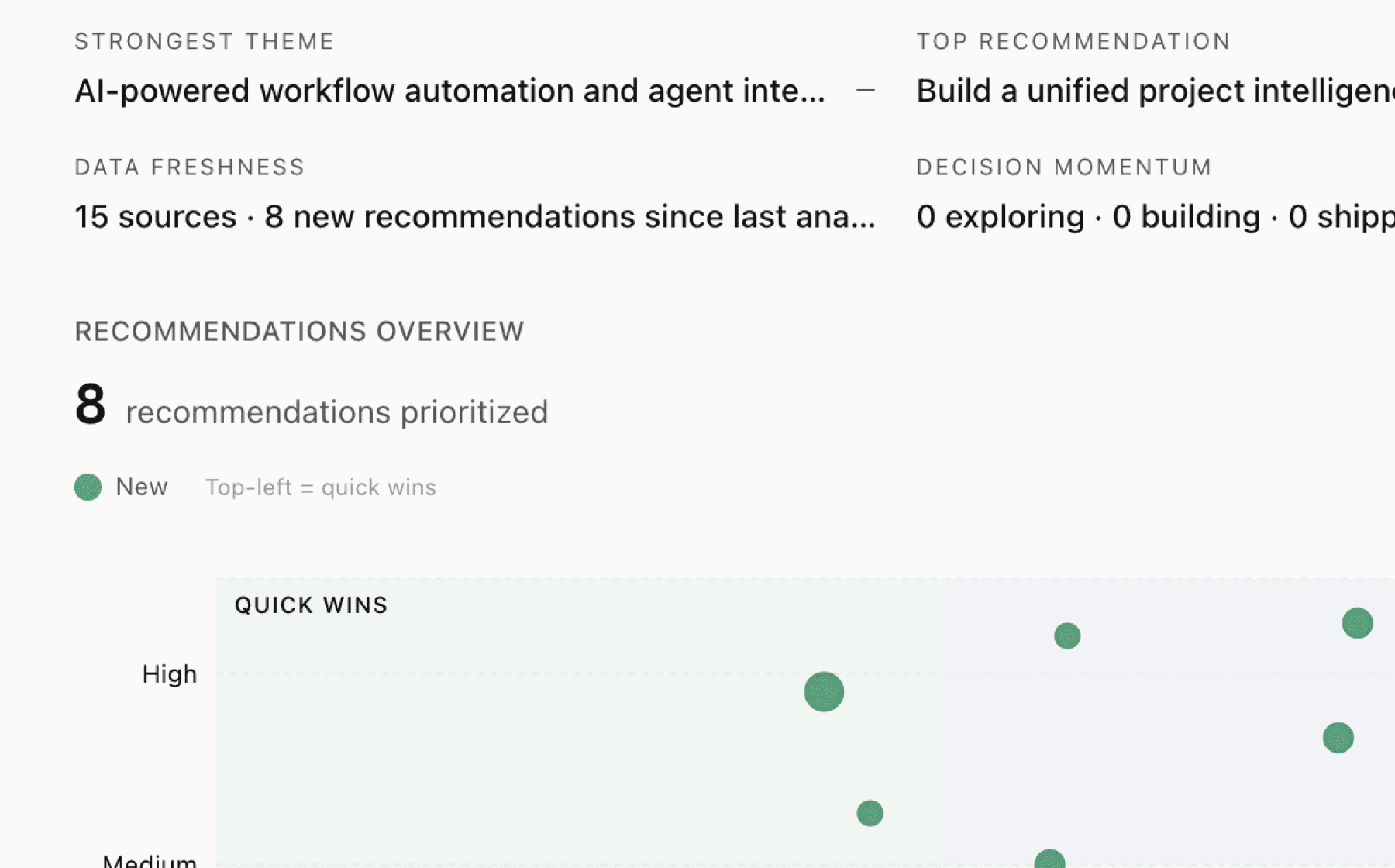
Mimir analyzed 13 public sources — app reviews, Reddit threads, forum posts — and surfaced 19 patterns with 8 actionable recommendations.
This is a preview. Mimir does this with your customer interviews, support tickets, and analytics in under 60 seconds.
Top recommendation
AI-generated, ranked by impact and evidence strength
Add native idempotency tokens to the append API with SDK-level automatic retry deduplication
High impact · Medium effort
Rationale
Transparent retry logic in SDKs currently causes duplicate records when appends succeed but acknowledgments fail — a fundamental correctness issue that forces every user to build custom deduplication. With 10 sources flagging this as critical, it's not an edge case. Users building agent sessions, multiplayer rooms, and IoT pipelines all need safe retry behavior as table stakes.
The primitives exist (writer UUIDs, per-writer indices, fencing tokens) but aren't integrated into a first-class idempotency guarantee. This creates unnecessary burden for developers who reasonably expect retries to be safe by default. Native idempotency tokens would eliminate a entire class of bugs and unblock users from building reliable systems without deep distributed systems expertise.
This addresses the gap between S2's positioning as enterprise-grade infrastructure and the reality that basic retry safety requires manual implementation. Given the platform's emphasis on correctness (linearizability testing, deterministic simulation), idempotency should be a core guarantee, not a user responsibility.
Projected impact
The full product behind this analysis
Mimir doesn't just analyze — it's a complete product management workflow from feedback to shipped feature.
Evidence-backed insights
Every insight traces back to real customer signals. No hunches, no guesses.

Chat with your data
Ask follow-up questions, refine recommendations, and capture business context through natural conversation.

Specs your agents can ship
Go from insight to implementation spec to code-ready tasks in one click.
This analysis used public data only. Imagine what Mimir finds with your customer interviews and product analytics.
Try with your dataMore recommendations
7 additional recommendations generated from the same analysis
The 1 MiB record limit forces users to implement custom framing for AI messages, images, audio, and video — exactly the rich data types driving adoption in agent sessions and collaborative applications. Five sources identify this as high severity friction, and the blog post explicitly walks through manual framing implementation, proving users are hitting this wall.
Multiple workers racing to checkpoint waste resources, Cloudflare subrequest limits cap throughput at 50-1000 appends, and individual HTTP POST requests create unnecessary overhead. The append session pattern with full-duplex HTTP/2 is already proven in production for KV replication and IoT pipelines — users just need it as the default interface.
Central coordinators lose work on crash with only the latest checkpoint recoverable, multiple workers racing to checkpoint waste resources, and streams grow unbounded without trimming. These are operational hazards, not abstractions users should manage themselves. The multiplayer rooms case study explicitly documents this pain, and the pattern applies across all multi-worker scenarios.
Users want to grant access to untrusted code (browser clients, third-party agents, embedded apps) without risk of abuse, but lack visibility into per-token usage and limit enforcement. Twelve sources flag granular access control as high severity, and the blog explicitly calls out usage limits as essential for safe delegation.
Agent sessions, multiplayer rooms, and distributed KV stores all converge on event sourcing patterns, but implementation is left to users. Twenty-one sources validate diverse use cases, and the blog posts provide detailed walkthroughs — the platform is enabling new architectural patterns but not packaging them for reuse.
Cost efficiency is a critical differentiator (4x cheaper than Durable Objects, transparent per-operation pricing, no cluster overhead) but users need to see concrete numbers for their workload. Eight sources flag cost as a driver, and the blog demonstrates specific comparisons, but this value isn't surfaced early in the evaluation journey.
S2 demonstrates product-market fit across diverse applications (agents, IoT, multiplayer, replication, CDC) but the onboarding experience is generic. Users arrive with specific problems and need to see their use case reflected immediately. The blog proves these patterns work in production, but new users face undifferentiated entry points.
Insights
Themes and patterns synthesized from customer feedback
S2 keeps the core data plane API intentionally simple (append, read, check_tail) to be transparent about guarantees, leaving higher-level functionality like branching, merging, and advanced state management to users. This design clarity trades off ease-of-use for transparency, placing significant burden on developers.
“S2 stream operations require only three fundamental operations: append, read, and check_tail”
S2 supports Server-Sent Events (SSE) for real-time updates over persistent HTTP connections with multi-language SDK support (TypeScript, Go, Rust, Python, Java) and REST API. A dedicated TypeScript SDK with optimized SSE support is requested to make it easier for developers to build real-time client applications.
“S2 supports Server-Sent Events (SSE) for real-time updates over persistent HTTP connections to clients.”
S2 simplifies IoT data ingestion by providing built-in durability and streaming, enabling both real-time consumption and historical replay for ML training without operational complexity.
“IoT data pipelines traditionally require complex infrastructure; S2 simplifies with built-in durability and streaming.”
S2 provides substantial throughput capacity with up to 100 MiBps per stream, addressing throughput limitations in competitive serverless offerings which have tiny ceilings on stream counts and throughput at premium prices.
“Write throughput capacity of up to 100 MiBps per stream”
Users have expressed interest in planned features like faster storage-class offerings with single-digit millisecond latencies and record timestamps in addition to sequence numbers to support evolving use cases and performance-sensitive applications.
“Supporting record timestamps in addition to sequence numbers (on its way)”
Active technical blog covering distributed systems, testing, AI, IoT, Rust, and TypeScript with use-case demonstrations provides developers with patterns and confidence to adopt S2 for complex scenarios.
“Content strategy emphasizes technical depth with categories: distsys, testing, AI, IoT, Rust, TypeScript, tutorials, and use-case demonstrations”
S2 meets SOC 2 compliance with granular access controls and organizational controls, supporting secure multi-tenant deployments.
“SOC 2 compliant with security best practices and organizational controls”
S2 demonstrates strong adoption across 8+ notable companies with diverse use cases including agent sessions, IoT data pipelines, multiplayer rooms, KV store replication, Postgres CDC, and serverless terminals. These cases show the platform enables new architectural patterns—particularly for event sourcing, distributed coordination, and collaborative applications—previously infeasible with traditional streaming.
“Used by 8 notable companies including Trigger.dev, Beam, SafeDep, and others”
S2 streams serve as public HTTP resources requiring fine-grained, revokable access tokens scoped to resources, operations, and optional transparent namespacing with pre-signed URLs. Users need visibility into usage and limits per token, plus flexible mechanisms to grant direct client access (browsers, apps, agents) without proxy layers for collaborative and agentic applications.
“Fine-grained access control is essential to bringing streaming data truly online”
Multi-worker coordination reveals friction points: central coordinators lose work on crash with only latest checkpoint recoverable, multiple workers racing to checkpoint waste resources, and streams grow unbounded without trimming. Append sessions with long-lived HTTP/2 streams are needed to bypass platform subrequest limits and improve operational efficiency.
“Central coordinator approach loses significant work if coordinator crashes, as only the latest checkpoint is recoverable.”
S2's 1 MiB record size limit requires users to implement custom framing schemes for larger payloads like AI messages, images, or audio. Built-in patterns and guidance would reduce developer friction for real-world use cases involving rich data types.
“Records have a maximum size limit of 1MiB, requiring users to implement framing schemes for larger data like AI assistant messages, images, or audio clips.”
S2 fills a critical market gap by combining real-time performance with durable cloud storage (Kafka-like durability plus S3 persistence) in a serverless model. This addresses the previous limitation where only enterprise platforms offered shared log services, enabling new serverless architectural patterns.
“S2 positions itself as 'Kafka and S3 had a baby' — combining real-time streaming with durable cloud storage”
Users struggle with implementing custom serialization and deserialization for stream records and need patterns and tooling for schemas and typing. Helper libraries like SerializingAppendSession reduce friction but remain a notable developer experience pain point.
“Users must implement their own serialization and deserialization logic for appending to and reading from S2 streams.”
Planned Kafka protocol compatibility as an open source layer with key-based compaction integration is requested. Users also need higher-level layers for consumer groups, queue semantics, and better parity with existing streaming platforms to reduce migration friction and enable easier adoption.
“Kafka protocol compatibility planned as open source layer with key-based compaction integration”
S2 decouples real-time consumption from data retention, allowing subscribers to replay from any point days in the past without ephemeral semantics. This architecture is validated by deterministic simulation testing, linearizability guarantees, and byte-for-byte log comparison ensuring strong consistency for mission-critical applications.
“S2 completely diskless with all writes safely persisted to S3 with regional durability before acknowledgment”
S2 delivers sub-40ms latency, sub-50ms p99 producer-to-consumer latency in same region, hundreds of MiBps throughput per stream, and support for thousands of concurrent readers without infrastructure tuning. These metrics validate serverless streaming at real-time scales and position S2 as a performant alternative to traditional infrastructure.
“Producer to consumer latency of <50ms p99 in same region”
Transparent retry logic in SDKs can cause record duplication if the original append succeeded but the call failed. Users currently lack formal idempotency mechanisms and must implement custom deduplication logic, creating a critical gap for safe distributed retry handling.
“Transparent retry logic in SDKs can cause record duplication if the original append succeeded but the call failed, requiring deduplication logic from users.”
S2 attracts users through zero upfront costs (no credit card required, first stream in seconds), transparent per-operation pricing ($0.05/GiB storage, $0.05-0.10/GiB reads), and 4x cost advantage over alternatives like Cloudflare Durable Objects. Pricing clarity and low cost-per-operation significantly reduce adoption friction.
“Current competitive serverless offerings have tiny ceilings on stream counts and throughput at premium prices”
S2 enables creation of unlimited streams with auto-create and auto-cleanup capabilities, allowing streams per device, user, session, or agent without operational overhead. This addresses core use cases like per-agent sessions and IoT pipelines where stream proliferation would be prohibitive on traditional platforms.
“Unlimited streams with auto-create and auto-cleanup capabilities, allowing streams per device, user, or session”
Run this analysis on your own data
Upload feedback, interviews, or metrics. Get results like these in under 60 seconds.