What TensorPool users actually want
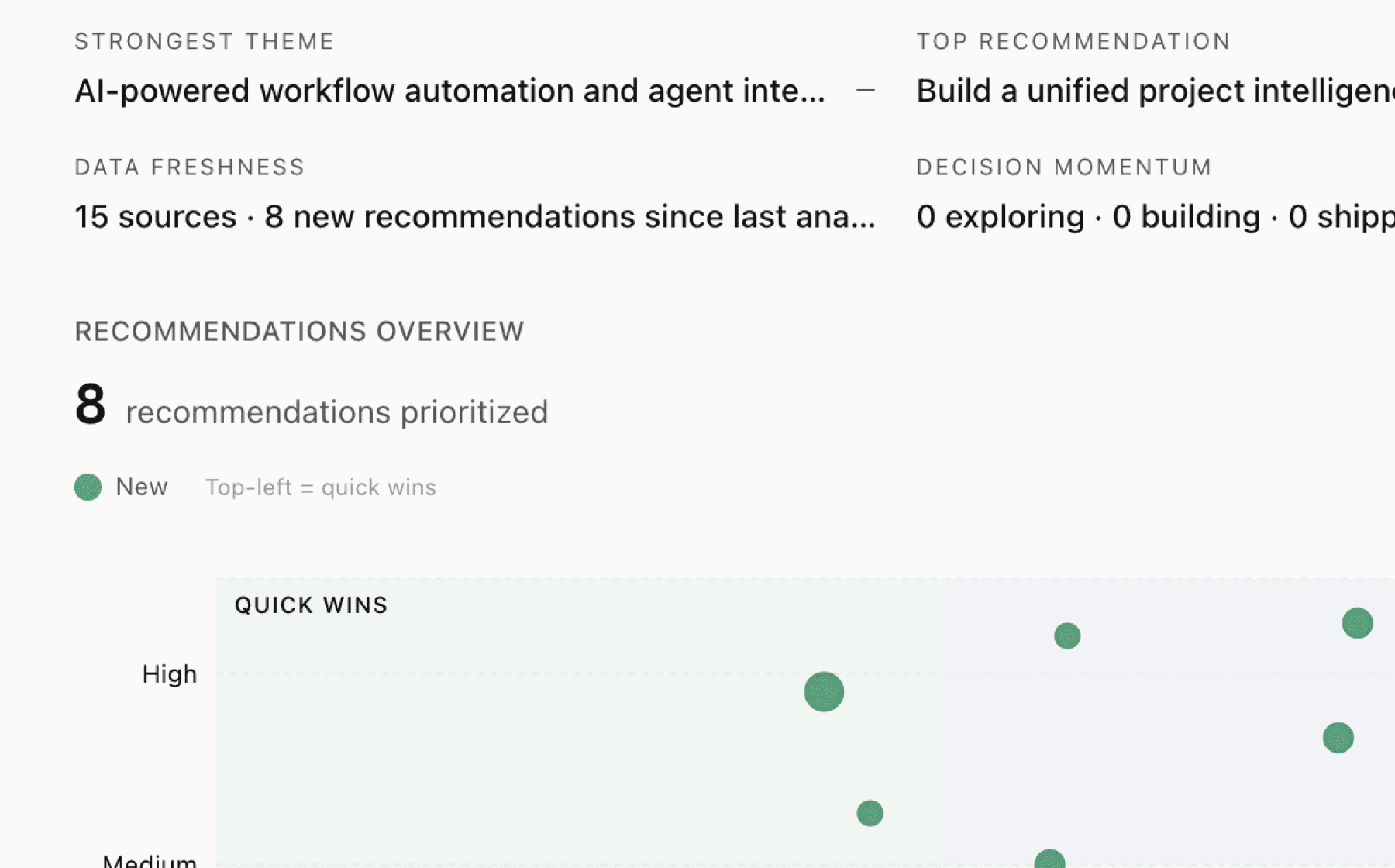
Mimir analyzed 12 public sources — app reviews, Reddit threads, forum posts — and surfaced 15 patterns with 8 actionable recommendations.
This is a preview. Mimir does this with your customer interviews, support tickets, and analytics in under 60 seconds.
Top recommendation
AI-generated, ranked by impact and evidence strength
Build an interactive GPU cost calculator showing total training economics across model sizes
High impact · Medium effort
Rationale
Users pay 2x more per hour for B200s ($4.99) versus H100s ($2.49) but achieve 50% lower total costs on models above 150B parameters — yet this counterintuitive value proposition requires mental math most buyers won't do. The evidence shows dramatic cost advantages (B200 saves $343,526 on 175B models, delivers identical costs on 70B models despite 2x hourly rates) but these insights are buried in blog content.
An interactive calculator would let users input model size, parameter count, and training duration to see break-even analysis in real time. This transforms complex technical content into a self-service sales tool that addresses the core friction: customers assume higher hourly rates mean higher total cost. Twenty-five sources discuss cost efficiency, making this the highest-frequency theme and the primary value driver for the product.
The calculator should surface GPU count recommendations, memory bottleneck analysis, and quantization savings (FP6/FP4 delivers 2-4x speedup) to help users make informed hardware choices. This directly supports user engagement by making pricing transparent and retention by ensuring customers choose cost-optimal configurations from the start.
Projected impact
The full product behind this analysis
Mimir doesn't just analyze — it's a complete product management workflow from feedback to shipped feature.
Evidence-backed insights
Every insight traces back to real customer signals. No hunches, no guesses.

Chat with your data
Ask follow-up questions, refine recommendations, and capture business context through natural conversation.

Specs your agents can ship
Go from insight to implementation spec to code-ready tasks in one click.
This analysis used public data only. Imagine what Mimir finds with your customer interviews and product analytics.
Try with your dataMore recommendations
7 additional recommendations generated from the same analysis
Storage delivers 46-180x faster throughput than traditional clouds (300+ GB/s vs 250 MB/s) but users can't see when slow I/O is wasting their $3-5/hour GPU spend. The evidence shows storage bottlenecks create hidden idle time during data loading and checkpointing, directly eroding the cost advantages users came for. Without visibility into GPU utilization and I/O wait states, customers can't validate they're getting value from premium infrastructure.
ZeroEntropy's case study demonstrates product value (compressed research timeline, achieved SOTA results, competed against well-funded incumbents) but this credibility signal is isolated in blog content. The evidence shows specific technical details matter: zerank model architecture, training methodology, GPU configurations, and infrastructure choices that enabled competitive success. These stories validate infrastructure quality for risk-averse buyers evaluating alternatives.
Nine sources emphasize transparent pricing as a trust-building mechanism, yet users must manually compare H100 costs across providers ($2.49 on TensorPool vs traditional cloud rates), factor in no egress charges, and calculate storage costs separately. The evidence shows TensorPool undercuts traditional clouds on GPU hourly rates while delivering superior storage performance, but this value is invisible without side-by-side comparison.
Users want batch hyperparameter sweeps, scheduled jobs, and multi-node distributed training but the current Git-style interface only handles single job submission. The evidence shows teams need to run multiple configurations simultaneously, execute jobs at specific times, and coordinate distributed training across clusters. TensorPool Jobs introduced configuration-as-code via tp.config.toml, creating the foundation for more sophisticated orchestration.
The break-even formula for GPU selection (B200 wins when (H100_GPU_count / B200_GPU_count) × speedup > (B200_price / H100_price)) is documented in blog posts but invisible during cluster provisioning. Users selecting instance types in the CLI see options (1xH100, 8xB200, etc.) but no guidance on which fits their workload. The evidence shows B200 is optimal above 150B parameters due to 2.4x more memory (192 GB vs 80 GB) but users must discover this through trial and error.
The CLI tutorial requires users to understand Python environments, API key setup, SSH key generation, and tp.config.toml syntax before running their first job. The evidence shows TensorPool targets product managers, founders, and engineering leads who want to focus on model development rather than infrastructure complexity, yet the onboarding flow front-loads technical setup. Users familiar with GitHub Codespaces or Replit expect zero-config environments.
TensorPool claims 300+ GB/s storage performance versus 250 MB/s on traditional clouds but users have no way to verify they're achieving these speeds with their specific data pipeline. The evidence shows storage bottlenecks are hidden and insidious (GPUs idle while data loads) yet performance claims rely on synthetic benchmarks, not user-specific validation. Seventeen sources emphasize storage performance as critical infrastructure, making this a core value proposition that needs proof.
Insights
Themes and patterns synthesized from customer feedback
TensorPool clearly discloses GPU/storage pricing with no egress/ingress charges, flexible trial/paid models, and transparent data collection practices. Privacy and pricing transparency reduce customer friction and establish confidence in cost predictability.
“L40S GPU hourly cost on traditional clouds”
TensorPool provides comprehensive CLI tools, SSH cluster access with pricing visibility, 24/7 Slack community support, and documented use cases spanning single-GPU development through multi-node training. This multi-channel approach reduces user friction and support response time.
“TensorPool provides SSH-based cluster access with IP addresses and pricing information displayed in cluster list”
High-performance NFS storage volumes attach only to multi-node clusters, not single-node instances, restricting use for smaller workloads and local development environments. This design constraint creates friction for teams requiring isolated development clusters.
“NFS storage volumes can only be attached to multi-node clusters, not single-node clusters”
TensorPool leverages partnerships with multiple providers (Nebius, Lightning AI, Verda, Lambda Labs, Google Cloud, Azure) to offer diverse on-demand GPU capacity. This network approach ensures availability across market conditions and reduces single-provider dependency.
“TensorPool leverages partnerships with multiple compute providers (Nebius, Lightning AI, Verda, Lambda Labs, Google Cloud, Azure) to offer on-demand capacity”
Services provided on as-is basis with limited liability capped at 12-month fees; customers bear responsibility for data compliance and security risk. TensorPool retains IP rights and restricts reverse engineering or unauthorized third-party access.
“Services provided on 'as-is' basis without warranties during trial usage, with additional limitations possible per Service Order”
TensorPool collects analytics data via cookies and logs (IP address, browser type, pages visited) for service improvement, using anonymized aggregated data. Service excludes users under 13 and discloses third-party provider access.
“TensorPool uses cookies to enhance user experience and gather analytical data, with some features potentially non-functional without cookie acceptance.”
TensorPool supports diverse instance types (H100, H200, B200, L40S) enabling teams to choose optimal hardware based on memory requirements, cost, and performance. This variety supports heterogeneous model architectures and training objectives.
“CLI supports multiple instance types: 1xH100, 2xH100, 4xH100, 8xH100, 1xH200, 8xB200, and more”
Customer case studies like ZeroEntropy's SOTA reranker training demonstrate TensorPool's value for research teams and startups, establishing credibility around infrastructure performance and support responsiveness. These examples compress research timelines and support competitive positioning.
“zerank models achieved state-of-the-art performance as open-weight rerankers across customer support, legal, finance, medical, and code domains”
Users seek familiar Git-like interfaces ('tp job push') for job submission to eliminate SSH complexity and configuration overhead. This enables configuration-as-code via tp.config.toml, supporting reproducibility, version control, and automatic resource cleanup without manual infrastructure babysitting.
“Git-style training job interface ('tp job push') to eliminate SSH access and reduce idle GPU time through familiar push/pull paradigm”
TensorPool offers true elastic, commitment-free access to multi-node clusters with guaranteed 3.2Tbps Infiniband networking and automatic scaling where storage persists across size changes. This eliminates the false choice traditional clouds force between long-term reservations and single-node instances.
“TensorPool abstracts GPU infrastructure complexity, allowing users to focus on model development rather than cluster management”
TensorPool CLI enables developers to provision clusters (1 to 128 GPUs) and storage with simple commands like 'tp cluster create', making infrastructure access familiar to teams comfortable with command-line workflows. This lowers operational overhead for infrastructure deployment.
“CLI-based GPU cluster provisioning with commands like 'tp cluster create' for multi-node clusters with guaranteed 3.2Tbs Infiniband”
Users require scheduled job execution, real-time GPU utilization monitoring, multi-node distributed training, and batch hyperparameter sweeps. These capabilities support research teams and startups running sophisticated training pipelines beyond single-job execution.
“Scheduled jobs: ability to run training at specific times”
TensorPool offers $1,000-$100,000 infrastructure credits to startups and academic institutions, directly enabling teams to accelerate model training and deployment without upfront capital. Programs are tailored to emerging companies and educational users.
“GPU infrastructure credits program ($1,000-$100,000) for startups and academic labs to accelerate ML model training and deployment”
B200 GPUs deliver 50% lower total training costs for large models (>150B parameters) despite 2x higher hourly rates, due to faster completion times and native compression support. TensorPool's pay-per-runtime billing and multi-GPU options (H100, B200, B300, L40S) position it as cost-effective against traditional clouds.
“H100 SXM GPU hourly cost on traditional clouds (GCP, AWS)”
High-performance NFS storage (300+ GB/s) is critical to scaling ML workloads beyond single nodes. Traditional cloud storage at ~250 MB/s creates hidden I/O bottlenecks that waste expensive GPU time; TensorPool's solution delivers 46-180x faster data loading and checkpointing, directly improving GPU ROI and total training costs.
“Traditional cloud storage (AWS EBS, Google Persistent Disk) delivers only ~250 MB/s reads, causing GPU idle time when paying $3/hour per GPU”
Run this analysis on your own data
Upload feedback, interviews, or metrics. Get results like these in under 60 seconds.