What The Context Company users actually want
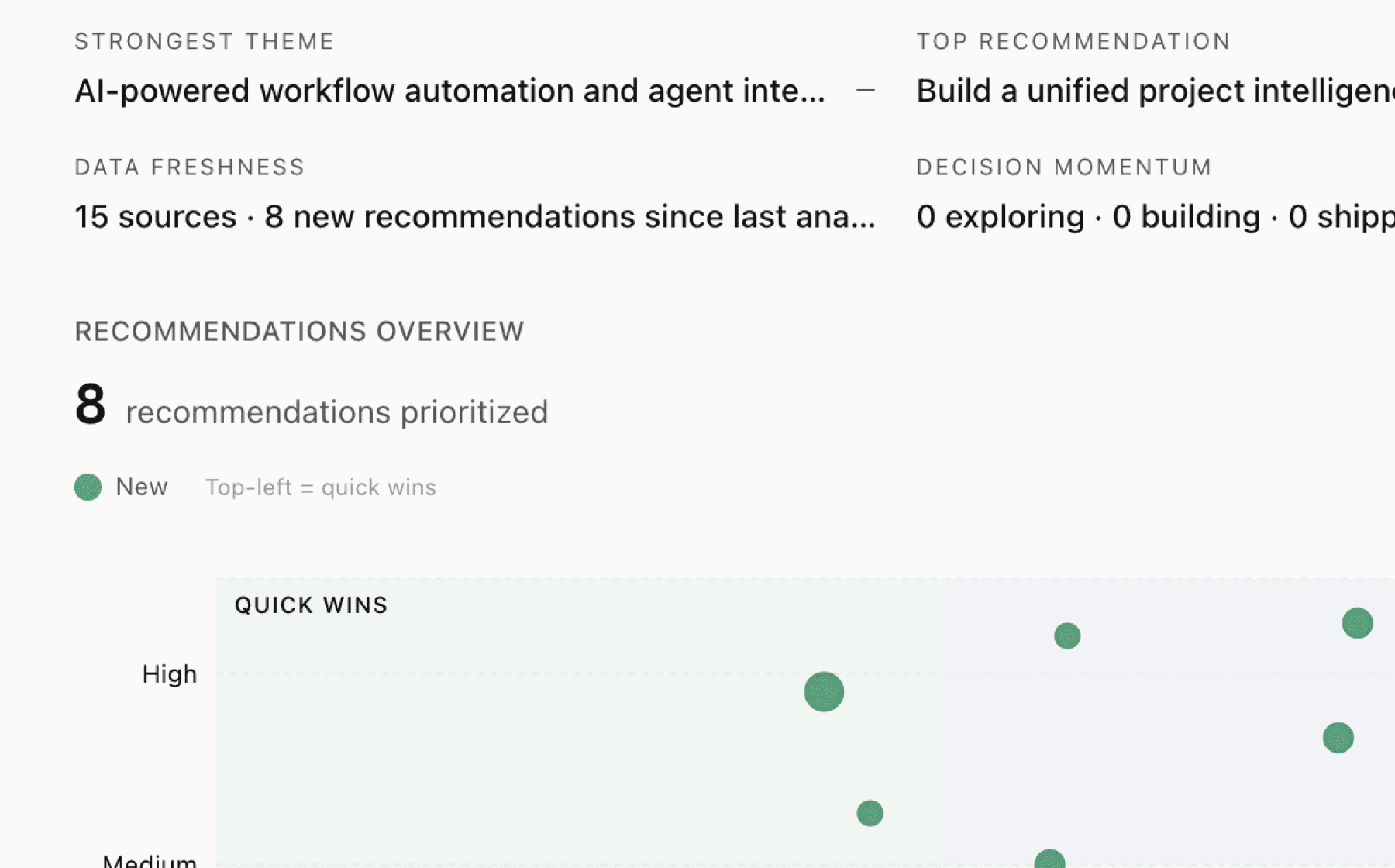
Mimir analyzed 5 public sources — app reviews, Reddit threads, forum posts — and surfaced 14 patterns with 6 actionable recommendations.
This is a preview. Mimir does this with your customer interviews, support tickets, and analytics in under 60 seconds.
Top recommendation
AI-generated, ranked by impact and evidence strength
Build automated silent failure detection that surfaces agent malfunctions without error signals
High impact · Large effort
Rationale
The 12.4% agent failure rate—three times normal levels—represents only the visible tip of the iceberg. Silent failures where agents malfunction without generating obvious error signals create blind spots that leave teams unaware of degrading user experiences. This gap is particularly dangerous because users experiencing silent failures may churn without providing feedback, making the true scope of the problem invisible until it's too late.
The current failure spike correlates with an 18% increase in refund requests and 42% increase in manager escalation mentions, suggesting that many failures go undetected until they escalate to critical business impact. Standard monitoring catches obvious errors but misses the subtle malfunctions that erode trust—agents giving plausible but wrong answers, making slightly incorrect tool calls, or gradually degrading in quality.
Automated silent failure detection would identify these issues proactively by analyzing behavioral patterns, response quality drift, and interaction anomalies. This capability directly addresses the observability gap that defines your product's value proposition and would differentiate you in a market where most tools only catch obvious errors.
Projected impact
The full product behind this analysis
Mimir doesn't just analyze — it's a complete product management workflow from feedback to shipped feature.
Evidence-backed insights
Every insight traces back to real customer signals. No hunches, no guesses.

Chat with your data
Ask follow-up questions, refine recommendations, and capture business context through natural conversation.

Specs your agents can ship
Go from insight to implementation spec to code-ready tasks in one click.
This analysis used public data only. Imagine what Mimir finds with your customer interviews and product analytics.
Try with your dataMore recommendations
5 additional recommendations generated from the same analysis
Agent misunderstandings directly damage user engagement through hallucinated details, infinite loops, and bad tool calls. Users experience confusion when agents fabricate facts, repeat questions, or make incorrect API calls—creating friction that drives the negative sentiment affecting 20% of feedback responses.
Teams currently lack efficient ways to identify systematic issues affecting multiple users. The feature request for topic clustering combined with the spike in refund requests suggests teams are manually sifting through feedback trying to understand what's going wrong—a time-intensive process that delays fixes.
Identifying failures is valuable, but teams need clear pathways from problem detection to fix implementation. The elevated failure rates and rising escalations suggest current tools leave teams knowing something is wrong without clear next steps for resolution.
The apparent contradiction between rising failure rates and 68% positive sentiment suggests complex user dynamics that teams need visibility into. While user frustration decreased 11% week-over-week despite a 4% increase in failure rates, the 18% jump in refund requests indicates that aggregate sentiment masks serious retention risks.
The current free tier provides 2,500 agent runs per month, which may constrain founders from fully validating your platform before committing to the $299/month Pro tier. Your target audience of founders building AI agent products likely needs extended evaluation time to integrate observability into their development workflow and demonstrate value to their teams.
Insights
Themes and patterns synthesized from customer feedback
The product targets founders and engineering teams building AI agent products with a multi-tier offering (Free, Pro, Enterprise) and multiple engagement channels (chat, email, Discord, calls). The positioning emphasizes helping teams monitor and understand agent behavior at scale.
“Target audience explicitly includes founders building with agents, suggesting product is tailored for early-stage teams and AI product builders”
The platform explicitly protects customer content (traces, logs, prompts, model inputs/outputs) by not using it to train foundation or product models unless users opt in explicitly. Data retention defaults to 30 days post-termination unless configured otherwise.
“Customer Content (traces, logs, prompts, model inputs/outputs) is not used to train foundation or product models unless users explicitly opt in in writing or via in-product setting”
The platform provides foundational observability through tracking of runs, steps, and tool calls with search and filtering by failure type and tool. This enables teams to drill into specific failures and understand agent behavior at granular levels.
“Core observability features include Runs, Steps, Tool Calls tracking with search and filtering by failure type and tool”
Users request topic clustering capabilities to automatically group and analyze patterns in agent interactions, enabling faster identification of systematic issues. This feature would reduce manual analysis burden and surface problems earlier.
“Topic Clustering feature to analyze and group agent interactions”
Thumbs-up/down ratings and text comments for user feedback are available in the free tier, enabling early-stage teams to collect sentiment and qualitative insights without paid features. This supports the primary goal of understanding user behavior.
“User feedback collection via thumbs-up/down and text comments is included in free tier”
The product offers three tiers with different usage limits: Free tier provides 2,500 agent runs/month, Pro tier provides 25,000 runs/month at $299/month, and Enterprise offers custom pricing. Data retention and team seat limits also vary by tier.
“Free tier provides 2,500 agent runs per month”
Despite rising failure rates and escalations, 68% of this week's 1,247 feedback responses carried positive sentiment, suggesting user frustration has slightly decreased 11% week-over-week. This indicates partial recovery or that positive users are more vocal than those affected by recent issues.
“This week received 1,247 user feedback responses with 68% positive sentiment”
67% of negative feedback is related to password reset issues, indicating a specific, high-impact UX problem separate from agent performance. This suggests a straightforward opportunity for improvement with potential significant sentiment lift.
“67% of negative feedback is related to password reset issues”
Agent failure rates recently spiked to 12.4%—three times normal levels—with a week-over-week increase of 4%, indicating systematic performance issues. This correlates with rising escalation signals, including a 42% increase in manager-related mentions.
“AI agent failure rate spiked to 12.4%, which is 3x normal levels”
Refund requests are the most common user topic in feedback, with mentions increasing 18% this week, while 20% of this week's 1,247 feedback responses carried negative sentiment. This indicates increasing churn risk directly tied to agent failures.
“Refund requests are the most common user topic discovered from conversations”
The broader market lacks tools to understand how users actually interact with AI agents, creating demand for observability solutions. This gap is particularly acute for founders and early-stage teams building agent products.
“Users need capability to understand how users interact with their AI agents, suggesting current tooling lacks visibility into agent-user interactions”
Users request the ability to detect frustration, confusion, and unhappiness signals from user interactions in real-time, enabling proactive intervention. This capability would help product teams identify deteriorating agent performance before it impacts retention.
“Detect when users are frustrated, confused, or unhappy with the AI agent through user intent analysis”
Users experience significant frustration when AI agents misinterpret requests, repeat questions, or provide confusing responses, directly impacting engagement. This friction stems from agents hallucinating details, getting stuck in loops, or making incorrect tool calls.
“Users experience confusion and frustration when AI agents misunderstand requests or repeat the same questions”
Current monitoring approaches fail to surface issues where AI agents malfunction without generating obvious error signals, leaving blind spots in observability. Users need explicit detection capabilities for silent failures to understand when agents are underperforming undetected.
“Standard monitoring misses silent failures—cases where AI agents fail without obvious error signals”
Run this analysis on your own data
Upload feedback, interviews, or metrics. Get results like these in under 60 seconds.